
/doh by striatic
In the first part of this discussion, I discussed the algorithms behind the Node.js-based Letterpress solver I wrote, called LetterPwn (source).
But I wasn’t just interested in making a cheater for a word game – I wanted to explore what it would be like to try to write a computation-heavy service in Node.js.
Many programmers – even Node.js aficionados – would say that’s a ridiculous thing to want to do.
They would say it goes “against the grain” of the platform, which is just a way for inexperienced programmers to whip up simple servers that perform pretty well.
I’ve got more experience than many, but I was interested in Node.js because, after all its infelicities, I still like JavaScript – it’s got just enough “good parts” to support functional programming, and modern implementations are blazing fast. On the client side, people are using it for CPU-bound tasks, like graph layout, all the time. It would be a pretty silly platform if we couldn’t do the same thing on the server when we wanted.
After doing this project my tentative conclusion is that Node.js can be a great choice for computation-heavy services. I’m not suggesting it should be your tool of choice for writing a movie encoder, but for the occasional CPU-bound task you might have when creating web-facing services, it’s got a pretty good toolbox. And it offers some scaling advantages you can’t get in other languages.
TL;DR
- cluster is the simplest way
- However, threads will force you to refactor into different services
- Which can run on other servers
- …or even the browser
The problem
LetterPwn is pretty fast – most results come back in a third of a second or less. But Node processes requests one at a time. Once you have a dozen or so people using the site simultaneously, those thirds of a second add up, and suddenly everyone starts cursing the spinning wheel on their screen.
And it is possible to craft a request to LetterPwn that would make it spin for even longer, absolutely killing performance for everyone else:
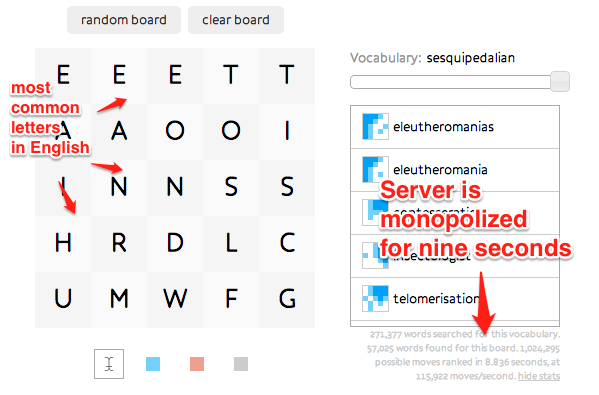
Most web apps don’t have this problem, simply because they don’t do much computation. They spend most of their time waiting for some other service to get back to them, like a database. The brilliance of Node is to exploit that fact, and use a very fast event loop which allows it to put a request on ice whenever it’s waiting for input. Meanwhile it goes off and serves other users.
3 Likes on Instagram
Blueboon is very tasty! by smarthero
But not every website is like this. What if we had an web service which applied 1970s filters to photos of overpriced beverages? There’s no input or output (I/O) there; the CPU is just grinding away at the pixels, probably for a few seconds. From Node’s perspective there’s no opportunity to switch tasks. Such tasks are called CPU-bound, versus the average website, whose tasks are I/O-bound. LetterPwn is just an example of such a CPU-bound service.
This model of sharing the resources of a computer is straight out of the 1980s, called cooperative multi-tasking. Every process has to voluntarily give up full control of the computer, or nobody else gets their work done. Every operating system you use today shares resources among tasks automatically.

In Node it’s even worse since that cooperation is usually implicit, based on a guess that input or output (I/O) is likely to happen soonish. So if you do real computation in Node, you suddenly become a very uncooperative single-tasker.
It turns out that you can solve these problems, with a number of techniques.
Being more cooperative

“Pass it on” by JeneaWhat
Typically, Node.js waits for some asynchronous I/O to yield to the next waiting process. But you can force that with
process.nextTick. (Update: as of Node 0.10 (changelog), you should
almost always use setImmediate instead.)
This is surprisingly efficient. I even got it working within forEach loops, and abstracted that into an nonBlockingForEach.
The price: if you thought Node programming had too many callbacks already, get ready to use them just to iterate through arrays, call a method, add some numbers together….
Even if you’re willing to accept that, you don’t always have a chance to even use process.nextTick.
At one point in my code, I call sort on an array which could have a million or more items. And as far
as I know, there’s nothing I can do to make that sort non-blocking, short of reimplementing it all over again in pure JavaScript.

So it looks like just cooperation1 isn’t going to work for us.
Getting more help

30Aug10 The Race-347 by WanderNeal
So if we can’t make our single process more cooperative, we’re going to have to get multiple ‘workers’ to attack the problem.
We can’t magically obtain more computing resources, but we can pop out of Node’s little world into the rest of the operating system, where processes can share resources without having to know about each other. That way, the Node event loop can just pass off a complicated calculation to one of these workers, and from its perspective, it can forget about it until it’s done.
Forking is the traditional solution for web servers like Apache. This creates the illusion that there are multiple isolated copies of the program running. Where secretly, the operating system ensures that they mostly reuse the same areas of memory. This makes it easy to have hundreds of forks open on the same machine, and if one gets stuck or dies, the rest chug along merrily. The downside is that communication between these forks is cumbersome, more like network communication.

In languages like Java, there’s a tradition of threading, where there are multiple paths of execution managed right in the same program, and data structures held in common. This approach has considerably more power, but even more opportunities to crash the program or put it into deadlock.
The twist: neither of these solutions are available in Node. It’s life, Jim, but not as we know it.
In Node, processes and threads share many characteristics. They have some of each other’s advantages and disadvantages.
Worker pools
Node taunts us by having a child_process.fork,
but it is all shameless deception. This is a fork and exec. So that means we will incur
the penalty of starting up an entire new Node process, with no shared resources at all (apart from filehandles and other aspects of the environment).
However, we will get a worker, in a separate process, managed by the operating system. Exactly what we want. There are quite a few libraries out there that can even help us manage pools of workers. I happened to use backgrounder.
Unfortunately, I was trying to do this whole project inside a single free Heroku dyno. That meant I got 500MB of space to work with. With the dictionary and all libraries loaded, including some function calls memoized with my lru-memoize library, my Node process was already pushing 200MB. So I could spawn exactly one worker process before maxing out, and that’s not even counting the usual fluctuations in memory use you get with a loaded Node process.

At best we would be able to serve two requests at once. Better than one, but it would still be completely blocked if it got two difficult requests at once.
Cluster
I originally thought the cluster module was a true copy-on-write fork, but it’s
not! Thanks to Doug Gale (doug16k) for actually reading the source. It seems the Node.js community decided
against ever doing that.
Nevertheless, cluster is by far the easiest way to use forking with Node. All we have to do is wrap the creation of the http server inside a very traditional forking structure (if parent, then do nothing; if child, start service).
My testing showed that using cluster was significantly more efficient - I’m not sure why yet, since it can’t be due to the benefits of copy-on-write.
But it was enough to run five to seven workers, more or less reliably. So this entire discussion could end right here.
There are a few issues; you can’t scale a simple forked server across machines. You’d still need some kind of load balancing proxy to direct requests to different machines.
So I continued to try a few more things, just to see…
Worker pools, hybrid approach
I realized that there already were two parts to my application:
- Finding words was data-bound; it needed to be close to a giant dictionary in memory, but it could be done in nearly constant time.
- Ranking moves was CPU-bound: it didn’t need to be close to data, or use so much memory, but required long processing times.2
So there was an obvious way to decompose the app; do the word finding in the main “loop” of the application. Dispatch to workers to calculate the best moves.
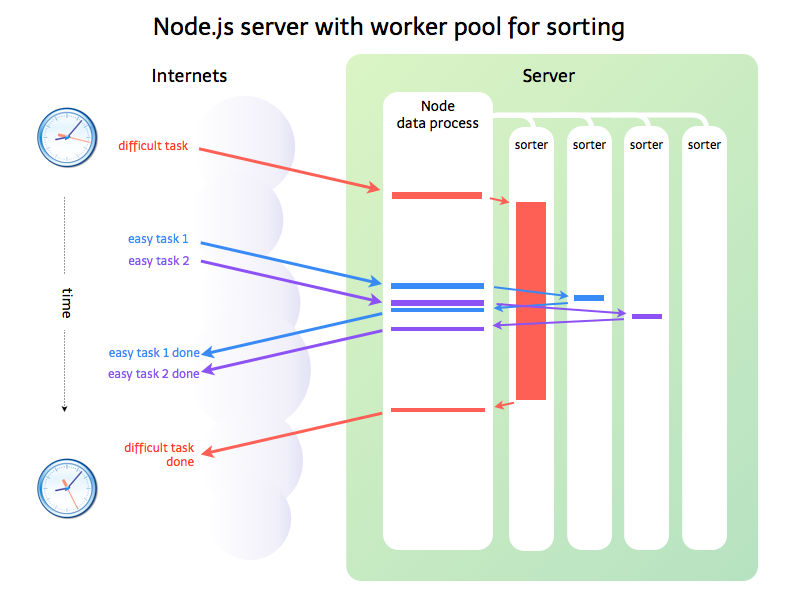
This also worked wonderfully. I could spawn at least five different workers within the free Heroku instance with room to spare. The workers can transiently balloon up to large sizes when they have to process huge dictionaries, but they quickly go back to normal after garbage collection.
I verified I could send it one of those 10-second nightmare boards in one browser tab, and still get quick results for easier boards in the other tabs.
There is still a lot of serialization and deserialization to manage as the server shuttles information in and out of the workers. We lost the advantage of simply accessing that giant data structure directly.
But there is one benefit; if we wanted to move these workers to a completely different server, or pool of servers, our code would barely change. So while Node forces the refactorings needed for this kind of scale out early, it will have benefits later on, if we need it.
Threads, hybrid approach
The worker pool approach was working well, but the memory fluctuations were still disturbing. Heroku will bring your application to a complete halt if you grab more memory than you are allocated, for some amount of time. I determined this was mostly related to the large serialization and deserializations involved. Also, the backgrounder library seemed to have some slow memory leaks, which I couldn’t track down. So I was looking for a slightly better solution.
Enter threads. threads_a_gogo is now the default way to do threading with Node. (I used
Audrey Tang’s fork, which solves an issue with building it on Macs.)
These threads are created and called in slightly bizarre ways. Even though they are still in the same process, you still communicate using serialized data, typically JSON, and you may eval code inside them to call their APIs. They don’t share any data, and they have to be a solid block of pure JavaScript.
You cannot use require to load in any code. If you need to load in libraries, you’re going to have to use a tool like
browserify
or onejs. Ironically, these are normally used to bundle up code from libraries, to be used in browsers.
So we have some of the same difficulties as processes. We can’t load in a lot of code or data, because it will be duplicated for each thread. But overall my testing shows that it uses far less memory, and it has a much more stable memory footprint, probably because the same memory is holding serialized JSON as it enters and leaves the threads.
There’s only one downside I can think of to using threads; if one of those threads went haywire, you couldn’t kill it with a simple kill command. You’d probably have to stop the entire web server.
The ultimate solution: code running on the server or the client
But now that we’ve got move ranking working inside of a separate process, with JSON-serialized messges, on a V8 instance, and no shared code or memory, another possibility arises; what if we simply did ran this on the client ?

We don’t want to run the word-finder algorithm on the client, because that would require a huge download of about 20MB to start with – maybe acceptable for certain kinds of browser-installed apps, but I wanted to keep this as a generic web service. However, we can move the move-ranker down to the client – it’s not a lot of code at all, it just takes a long time to run. Modern JavaScript implementations are just as fast as Node - it only exists because of all the research poured into JS engines lately.
I tried this by simply concatenating the entire move-ranker into the interface JavaScript, and it worked great. The only problem was that the interface came to a complete halt. Even my spinning animated GIF froze.
What we need is an abstraction that allows us to have the same kind of parallelism that we have on the server, with processes and threads, on the client. The solution: Web Workers.
Web Workers are a standard for Javascript parallelism that have been brewing since 2009 or so, but they’re just becoming practical now as most web browsers, with the exception of the usual suspects, are supporting them well. (I tried this in late 2011 and it was a non-starter for image processing.) Web Workers have all the power of browser scripts, except they are not allowed to touch the DOM in any way. But we don’t care about that here – it was code running on the server anyway. We had to use browserify on the server, so with slight alterations to the API, we can use that again on the client. In many ways a Web Worker is exactly analogous to an ordinary HTTP request that you might handle with XHR, except it’s handled locally.
Most modern browsers can run Web Workers, but we still need to be ready for the ones that can’t. So here’s the plan:
- We test for the presence of Web Workers in the browser.
- If we have Web Workers, we ask the server to give us just the words that match our board, and we’ll figure out the moves locally.
- If not, we ask the server to do it all.
This works beautifully. The big dictionary stays where it is, and we serve requests for word-finding in tiny fractions of a second. More complex work is farmed out to our threads, and for many browsers, we can dispatch work off to the browser itself.
It’s not a perfect solution, since we incur the overhead of more I/O. In LetterPwn’s case, it might be sending a lot of JSON down to the client, which the client then boils down to just a few recommended moves. But the general pattern is a good one, especially if we can use it to avoid making subsequent requests to the server at all. We can apply this to any sort of ‘last-minute’ massaging of database search results, particularly pagination or sorting.
Conclusion
I wanted to see if Node.js was a practical solution, and I was more than satisfied. In the world of web apps, we often use highly dynamic languages with simple programming models.
But now Node.js is bringing a few other things to the party: easy background tasks, without really giving up our original simple programming model. And we can also keep giant data complex structures persistent in our request process, something which you can’t do at all in languages like PHP.
The real revelation is that we can now offload a lot of processing to the client, without any extra development time. Add a few automated scripts to recompile the ‘browserified’ scripts and you’re done.
Now we don’t have to think in terms of “server” and “client”, we now should think of what needs to be close to the server’s data, or is deeply entwined with it. Frameworks that blur the client-server distinction, like Meteor, Hoodie and more are cropping up on a daily basis.
The title of this blog post is a little provocative. Of course Node.js still has some pretty large defects, as a young platform, based on a language not known for its friendliness to programmers looking for computational performance.
But I’m not only sticking to the title’s claim, I’m even starting to believe it myself!
Postscript
I turned this blog post into a talk at Vancouver Node Brigade in December 2013. Here are the slides in PDF form.
Notes
Fibers give us another cooperative model, but they aren’t relevant to our problem. Fibers are more of a code organization pattern than a way of doing concurrent tasks.
In theory, the complexity of this task is O(n!), where n is the number of words on the board, since combinations are involved. But in practice, this never happens, because if you can play one word almost everywhere on the board, that means other words can’t be played in as many ways. So it’s more like O(n), although with a large constant (a maximum of about 20n). I don’t think there are boards with more than 1.5 million moves to consider.
Thanks to Audrey Tang and Jan Lehnardt who reviewed drafts of this post.